■DNAコンピュータ
- エイドルマンの発想
DNAコンピュータの誕生 - DNAポリメラーゼとチューリング機械の類似性
今から50年ほど前にワトソンとクリックがDNAの二重らせん構造を提案した。DNAは巧みな二重らせん構造によって、生物にとって重要な情報の保存・複製を可能にしていることが分かった。しかもその情報密度は、DNA1gあたりでCD三兆枚分にも匹敵するほどだ。そのことを考えると、以前からDNA分子やその構造を利用してメモリなどに利用しようとする試みはあったに違いない。
ところが、DNA分子を演算装置として利用できることが実証されたのは1994年のことで、この実験は南カリフォルニア大学のエイドルマン(L.M.Adlemen)によって報告された[1]。これがDNAコンピュータのはじまりでもあるが、同時にその実験は分子コンピュータとしても初めてのものだとされている。
エイドルマンがDNAコンピュータを思いついたきっかけはなんだったのだろう?RSA公開鍵システムの開発者の一人でもあるエイドルマンは、もともとはコンピュータサイエンスを専門にしていた。しかし、93年ごろに、エイズに関する研究に参加する機会にめぐり合い、分子生物学の知識になった。そんな状況でエイドルマンが、ワトソンの分子生物学の教科書を読んでいたときに、「DNAポリメラーゼ(DNA polymerase)」の役割と、「チューリング機械(turing machine)」との間に類似性があることに気づいたのがDNAコンピュータ誕生のきっかけとなった。DNAポリメラーゼは、DNAの塩基配列を読み取り、相補性的な塩基配列のDNAを複製する酵素である。一方、チューリング機械は、入力テープを読み取り、一定の計算処理を行なって出力テープを打ち出すというものだった。DNAポリメラーゼもチューリング機械も、「入力→処理→出力」という点では共通している。しかも、DNA鎖やテープを読み取るなどといった物理的な役割も似ている。こうしてDNAポリメラーゼの役割にヒントを得たエイドルマンは、DNAコンピュータの製作にとりかかった。
DNAコンピュータの基本的な性格
DNAコンピュータは、シリコンを中心としたコンピュータとは仕組みが大きく異なっており、それによって得意不得意とする分野も違ってくる。
基本的に従来のコンピュータには、中心にマイクロプロセッサがひとつ存在しており、それが信じられなほどの速さで次から次へと計算処理をこなしている。一方でDNAコンピュータの場合は、分子一つ一つの処理速度は必ずしも高くないが、1度に何万、何億という分子が並列してさまざまな計算処理を行なうことが可能になる。そのためDNAコンピュータは、従来のコンピュータが苦手とする「ハミルトニアン経路問題」などが得意だと考えられている。これは計算処理の件数が指数関数的に増えていくという問題だ。DNAコンピュータといってもさまざまなタイプがあるが、並列処理が得意だという点ではほぼ共通しているだろう。
エイドルマンがDNAコンピュータの製作にとりかかったとき、DNAコンピュータに解かせた問題というのが、このハミルトニアン経路問題の一つである「セールスマン問題」だった。
エイドルマンがはじめて作ったDNAコンピュータ
まずはじめに、エイドルマンがDNAコンピュータの計算処理の対象とした、セールスマン問題がどのようなものか知っておいたほうがよいだろう。具体的には、次のような内容だ。
あるセールスマンが飛行機に乗って、セールスのために、いくつかの都市すべてを立ち寄らなければならないとする。ただし、このとき重要なのが、すべての都市どうしがエアラインで結ばれているわけでないということと、一度通った都市は二度と通ってはいけないという、2つの制限があるということだ。これがセールスマンの悩みの種となっている。
このフラッシュアニメーションの場合、「長崎」から出発して、「広島」、「大阪」、「東京」のすべての都市を一回ずつ立ち寄り、目的地である札幌に向かわなくてはならない。どのように旅行計画を立てることができるだろうか?この程度の問題なら簡単だろう。答えは「長崎>東京>広島>大阪>札幌」という順になる。
この程度の数の都市とエアラインなら、紙や鉛筆を用意するまでもなく、頭の中で簡単に解けてしまう。しかし、都市の数が増えると、それを結ぶエアラインの数も急激に増えてくる。おそらく都市の数が10を越えるころには、頭の中では解けなくなり、コンピュータに頼ることになるだろ。しかし、今のコンピュータでも1万都市を超えるとなると、ハイパワーのものをいくつか同時に稼動させても数日はかかるだろう。いずれにしても、ハミルトニアン経路問題というのは、現在のコンピュータにとってはあまり相性のよい問題ではない。
この問題は数学的にもコンピュータサイエンス的にもよく出てくる古典的なものだ。では、エイドルマンはどのような方法で、これを解くことに成功したのだろうか?いくつかのステップに分けて考えてみよう。
[step1 考えられうるすべての旅行計画を手当たり次第つくる]
何はともあれ、コンピュータが「0/1」の文字に置き換えて処理しているように、DNAコンピュータもDNAの扱いやすい文字、つまり「A,T,C,G」に置き換えてやる必要がある。そこで、5つの都市を区別できるように、次のように置き換えてやる。以下のようなDNA断片をつくる。
| 「長崎」 |
ATGCCG |
| 「広島」 |
TCGTAC |
| 「大阪」 |
GCTACG |
| 「東京」 |
CTACGG |
| 「札幌」 |
CTAGTA |
(※置き換え方にとくに決まりや法則性はないが、下で述べるエアラインと合わせて、お互いの都市が区別できればよい。)
次に、「長崎>広島」、「東京>大阪」など、それぞれのエアラインをDNAの文字に置き換えてやらなければならない。ここで、都市名とエアラインをうまく対応させる方法がないか考えてみよう。そこで「広島>大阪」の場合なら、「広島(ATGCCG)」の後半の3文字'CCG'と、「大阪(GCTACG)」の前半の3文字'GCT'をくっつけて'CCGGCT'を考え、これと相補性をもった'GGCCGA'を「広島>大阪」を表すエアラインとする。逆に「大阪>広島」なら'ACGATG'と相補性を持つもの、つまり'TGCTAC'となる。
この方法で置き換えれば、旅行経路を、都市の順番(「長崎」>「東京」>「広島」>「大阪」>「札幌」)に並べた'ATGCCGCTACGGTCGTACGCTACGCTAGTA'と、エアラインの順(「長崎>東京」、「東京>広島」、「広島>大阪」、「大阪>札幌」)に並べた'GGCGATGCCAGCATGCGATGCGAT'が、頭尾の3文字を除いて相補性を保っているという仕組みになっている。
あとは、都市とエアラインを表すDNA断片を試験管のなかに放り込むだけだ。そのときに小さなDNA断片を結合する「DNAリガーゼ」という酵素を一緒に入れておけば、小さなDNA断片は一本のDNA鎖になる。都市名を表すDNA断片とエアラインを表すDNA断片が、お互いにくっつき合って、答えとなる旅行計画書(目的のDNA断片)が自然とできあがるというわけだ。(DNAリガーゼについては、「DNAコンピュータ/DNAの構造と複製機能」を参照」)
もちろんこれだけで、正しい旅行計画を表すDNA断片だけができるわけではない。むしろ正しい計画書はほんのわずかで、あとのDNA断片の集まりは数が足りなかったり配列が間違っていたりと、デタラメなものばかりができているはずだ。そのため、正しい旅行計画に相当するDNAだけを取り出してやる必要があるのだが、それはまるで大草原の中から小さな藁を拾い上げるようなもので、簡単なことではない。
それでは、どのような方法で、目的のDNA断片を拾い上げるのだろうか?
[step2 デタラメな旅行計画書の山から、正しいものを取り出すには…]
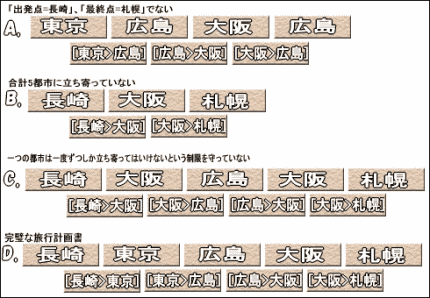
条件を満たしていないDNA断片(A,B,C)と目的のDNA断片(D) |
試験管の中には、さまざまの長さや配列のDNA断片が存在しているはずだ。そんな中でも、まずは出発点が「長崎」、最終地点が「札幌」になっているもの、つまりDNA断片の端が「長崎」と「札幌」を表す配列になっているものだけを拾い上げたい。これは、「ポリメラーゼ連鎖反応(PCR)」で「プライマー(primer)」という相補性を持ったDNA小断片を利用することで可能になる(ポリメラーゼ連鎖反応の大まかな仕組みを理解していないと、以下の文章が分かりにくいかもしれない。ポリメラーゼ連鎖反応については、「DNAの基礎知識/DNAの増幅 - ポリメラーゼ連鎖反応」を参照)。
1.今必要とされるDNA配列は出発点が「長崎(ATGCCG)」で最終地点が「札幌(CTAGTA)」のものだ。そこで、それと相補性をもったプライマー「長崎'(TACGGC)」と「札幌'(GATCAT)」を用意する。これによって、端に「長崎」と「札幌」をもつものばかりが複製される。
しかしこの時点では、「長崎」と「札幌」の間にくる都市の順序が間違っていたり、長すぎたり短すぎたりと、デタラメな旅行計画書が多く残っているはずだ。ただ、とにかくこれで出発地点が「長崎」、最終地点が「札幌」の計画書だけに絞り込むことができた。このとき図のAは取り除かれている。
2.次に、上で選択した計画書の中から、5つの都市だけを通っているものだけを選び出してみよう。ここでは、ゲルの上にDNA断片を染み込ませ両側から正負の電気をかけて、負に帯電したDNA断片を泳がせる「電気泳動」という操作を行う(電気泳動については、「DNAの基礎知識/電気泳動」を参照)。
このとき、DNA断片の長さ(重さ)に応じて、泳ぐ距離が変わってくるので、30塩基対(6塩基対×5都市)のものだけを選び出すことができるというわけだ。こうして図のBは取り除かれる。
これでだいぶ計画書を絞り込めたが、まだデタラメなものが含まれている。例えば「長崎>大阪>広島>大阪>札幌」(図のC)というような計画書が含まれているはずだ。つまり、すべての都市を1度だけずつ立ち寄るという条件を満たしていないものだ。そこで、今度はすべての都市に立ち寄っている計画書だけを選ぶために、次のような方法を考える。
3.たえば、東京(CTACGG)に立ち寄る計画書を拾い上げるために、東京と相補性をもった「東京'(GATGCC)」というDNA断片で、計画書のDNA断片を探す。このとき東京を含んでいない計画書があれば、それは「東京'」とうまくくっつかないので拾い上げられることはない。つまり、「長崎>大阪>広島>大阪>札幌」という間違った計画書はそのまま見捨てられてしまうというわけだ。こうして、5都市すべてに相補性をもったDNA断片で拾い上げの操作を行う。
この一連の結果得られるものは、出発は長崎、最終は札幌で、5つの都市すべてを5回だけで旅行するというもの・・・つまり、それこそが完璧な旅行計画書なのだ(図のD)。
[step3.完璧な旅行計画書の都市の順番を吟味する]
さて、完璧な旅行計画書を選び出すことはできたが、実際に塩基配列を読んで都市がどのような順番で並んでいるかがわからなくては、旅行計画書を書いたことにはならない。現在では、直接DNAの塩基配列を読むことのできる特殊な顕微鏡(AFMなど)があるが、それらを使わない方法を考えてみよう。
ここではstep2のはじめに行ったプライマーを利用したポリメラーゼ連鎖反応(PCR)を行う。例えば、「大阪」の位置にプライマーを取り付けてPCRを行うとしよう。すると「長崎、…、大阪」のDNA断片ができる。それの塩基数を数えれば24塩基となるはずだ。したがって24÷6=4で大阪が4番目ということになる。
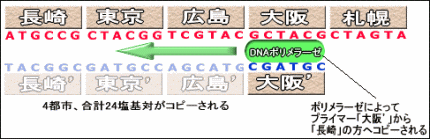
DNA断片の塩基配列に何が書かれているかを知る方法 |
あとは同じようにして、「東京」、「広島」とプライマーをつけてPCRを行えば、12,18塩基となり、2番目、3番目と判断することができる。
これでついに完璧な旅行計画を書き上げることができたわけだ。ついに出張セールスマンの悩みは解消された。
より大きな問題を解くには・・・
94年にエイドルマンが行なった実験では、7都市14エアラインのセールスマン問題が対象となった。この実験はDNAコンピュータ、さらに分子コンピュータの世界に大きな影響を与えた。しかしこの方法で、実用化を目指そうとするとき、大きな障害が姿をあらわす。
都市数を増やしていくこと、つまり、変数の多い複雑な問題を解くときに、物理的制約が大きな障害となってくるのだ。例えば、次のようなものが挙げられる。
1.操作ステップ数が増加する
2.誤差が蓄積する
3.候補の解として用意するDNA分子の数が増加する
実は、1に関しては、それほど致命的な問題ではないかもしれない。現在も発展を続けているバイオテクノロジーや半導体加工の技術を援用すれば、ほぼすべてのステップの操作を自動化することも不可能ではないだろう。
2のエラー率の問題は、重要なポイントである。基本的に、ステップを重ねることに誤差が蓄積して行くので、規模の大きな問題を解くときには、最終的な解がまったくデタラメなものになってしまうかもしれないからだ。
さらに厄介なのは3である。仮にエラー率の障害を克服できたとしても、それだけでは3の障害は解決しない。
従来のコンピュータではハミルトニアン経路問題などを解くには、変数の数に応じて指数関数的な時間が必要だった。一方、DNAコンピュータの方は、指数関数的に増える解の候補を表現するDNA分子をあらかじめ用意しておかなくてはならない。ということは、問題の大きさによっては、必要なDNA分子が地球の質量分というように非現実的な値となることがある。仮にそれだけの量のDNA分子を用意できれば、DNAコンピュータは並列的にその問題を解いてくれるだろうが、そのための準備をするのは現実的でないというわけだ。この解決には必要なDNA分子の数を減らせるようなアルゴリズムが必要となる。
ref.
[1]L.M.Adlemen,"Molecular computation
of solutions to combinatorial problems",
Science 266, 102(1994)
|
|


