|
 |


|
最終更新日:2002/12/9


|
■自己組織化&自己集合
- 超分子の世界へ
高次な分子認識
さらに分子認識は、もっと高度な集合も誘発する。一般に金属イオン(中心金属原子)と有機分子(配位子)などの集合体(錯体)は、金属イオンの種類によってさまざまな幾何学的構造を作る。先ほどのクラウンエーテルはホストとゲストの1:1の関係で、ポリロタキサンは1:多数だった。しかし、ここでは多数:多数といった、より大きな集合体をつくることが可能となる。ここでは集積化錯体を利用した例と、DNA分子を利用した例を見てみる。
幾何学的構造の宝庫である無機錯体の自己集合
 |
無機化合物の自己集合・自己組織化には、らせん構造や格子構造など、かなり明確な幾何学的構造を自発的に形成するものがある。
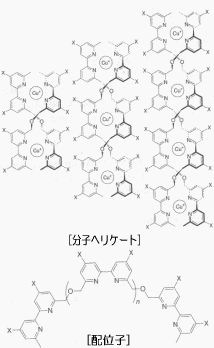
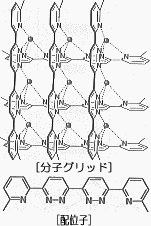
たとえば、ある金属イオンと有機化合物系の配位子を存在させておくと、状況によって、らせん構造をもったヘリケート(helicate)型、そろばんのような形のロタキサン(rotaxane)型、そしてコンピュータのメモリ素子を彷彿とさせるグリッド型などの幾何学的な構造を自己形成する。実際、このような構造をとっていることは分光学的データから分かっている。
この安定な幾何学的構造はいったいどこからやってくるのだろうか?
それを理解するためには、まず金イオンのいくつかの特徴を知っておかなくてはならない。
1.錯体形成によって、一連の幾何学的配列を誘導する。
錯体の幾何学的構造は、四面体、平面四角形、八面体、三角円柱など、基本的なものだけでも実に多様だ。
2.結合強度、結合および解離速度の幅が広い。
これによって特定の金属イオンと配位子だけが錯体をつくるといった選択性が生じてくる。
3.電気化学的、光化学的、磁気的性質などの多様性。
超分子系錯体をデバイスとして利用するとき、金属の電気的、光学的、磁気的性質はデータを蓄えたり取り出したりするのに不可欠となってくる。
こういった性質をもつ金属イオンと有機化合物配位子による自己集合や自己組織化には興味深い点がいくつもある。
まずは選択性によって幾何学的構造がどう変わってくるかを見てみよう。
ヘリケート型は金属イオンとオリゴビピリジン鎖からなっているが、ここでどの金属イオンを選択するかによって、ヘリケート構造は大きく変わってくる。例えば銅イオン(Cu+)だと四面体型錯体を形成するので、2本のオリゴピリジン鎖が銅イオンのまわりに規則正しくらせんを描く二重ヘリケート構造になる(下図)。ところが八面体型錯体を形成するニッケルイオン(Ni2+)の場合は、三本のオリゴピリジン鎖からなる三重ヘリケート構造になる。
一方、金属イオンはCu+のままにして配位子の方だけを変えてみても、別の面白い変化が現れる。配位子を図2のものに変えると、ヘリケート型ではなくグリッド型になる(下図)。
しかも面白いことに、二重ヘリケートと三重ヘリケートの成分が並列して反応している場合でも、互いに妨害したりのりかえしたりすることはなく、あらかじめ決められた異なる二つの自己処理過程が同時に進行する。
DNA分子の高度な認識を利用する
自己組織化はコントロールすることが難しく、例えばLB膜・自己組織化膜などのように、単純な繰り返し構造しか作ることができない。しかし何らかの方法で、自己集合をコントロールできれば、任意の複雑な二次・三次構造も自由に造ることができるはずである。
これを可能にする一つの方向性が、DNAの「プログラム化された自己集合(programmable self
assembly)」である。これによってDNAコンピュータやナノマシーンなどの作成が試みられている。
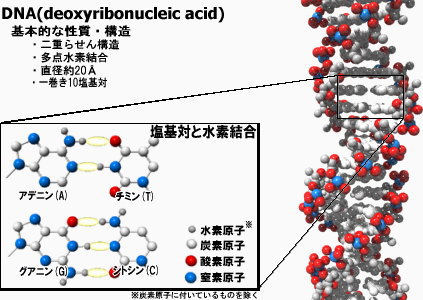
DNA(deoxyribonucleic acid)の最も基本的な構造は、WatsonとCrickが最初に提案した二重らせん構造である。それぞれ2本の鎖は、アデニン(A;adenine)、チミン(T;thymine)、グアニン(G;guanine)、シトシン(C;cytosine)の核酸塩基をもつヌクオレシドが、リン酸ジエステル結合で1次元につながったポリマーになっている。
生体内ではこの2本の鎖が水の中で会合しているわけであるが、水和されやすいリン酸ジエステル部分は外側に、疎水的な核酸塩基は水を避けるように積み重なって内側に集まる。そして塩基部分の相補的な水素結合パターンにより、AT,CGという二種類の塩基対が形成される。
基本的に水素結合は共有結合と比べて弱く、穏やかな条件下でも簡単に切れてしまう。そのため、それぞれの塩基対どうしの水素結合が多く連なって多点結合することで安定性を得ている。
しかし、DNAの二重らせん構造はあくまで「やわらかい」もので、酵素の助けなどを借りて、温和な条件で分離・結合し、複製やタンパク質の合成を可能にしている。(DNAの複製過程については「DNAコンピュータ/DNAの基礎知識」も参照。)
今や、ある程度の長さの塩基配列はカタログを見て注文できるような時代になった。塩基配列は全自動合成機を用いれば好みのものが得られるし、鋳型DNAがあれば、PCR(ポリメラーゼ連鎖反応)で数時間のうちに何百万倍にも複製することもできる。
こうして用意したDNAを利用して、二重らせん構造以外の三次元的な分子構造を構築する研究が行なわれている。
この研究に関しては、「DNAテクノロジー」の創始者であるN.Seemanが有名である。これまでにSeemanは、DNAから立方体、多面体、タイルなどさまざまな形のブロックを作り出している。これらは、何本かの2本鎖DNAがその一本鎖を何箇所かで交換することで合体してできた構造である。
 Ned Seeman's Laboratory Home Page - NYU Ned Seeman's Laboratory Home Page - NYU
(N.Seemanの研究室のページでは、DNAブロックのCGを多数見ることができる)
さらにこのブロックを集積化して、レゴブロックを組み立てるかのように、複雑な三次元構造を作り出すのにも成功している。複雑な三次元構造が可能なのは、カーボンナノチューブなどの単純な繰り返し構造と異なり、塩基配列の組み合わせの複雑さから高度な選択性が生じるためだ。
あらかじめ最小構成単位となるDNAブロックを考慮して設計することで、自己集合を間接的にコントロールすることができるというわけだ。
分子プログラミング
ここで一つ面白い発想をとってみよう。これまで話してきた分子認識から高度な自己集合までの過程を、情報科学の用語を使って整理してみてはどうだろうか。
まず、タンパク質の折りたたみは、ポリペプチド鎖に含まれるさまざまな官能基が互いに結合することによって生じる。ポリペプチド鎖の官能基配置はアミノ酸配列によって決まるわけですから、ある意味、タンパク質のとる立体構造の情報はアミノ酸配列のなかに組み込まれているともいえるだろう。つまり、アミノ酸配列のなかにタンパク質の立体構造についての情報がプログラムされているというわけだ。
錯体の自己集合もこのタンパク質の話と似ている。グリッド構造かヘリケード構造かは、配位子の分子構造によって変わってくるわけだが、これもあらかじめ分子に構造の情報がプログラムされていると考える。もちろん相手の金属イオンが変われば、同じ配位子を使っていても最終的な構造は変わってくるので、分子にプログラムされている情報というのはあくまで相対的なものだ。
一般に私たちの世界では、ハードウェアとソフトウェアは明らかに区別ができて、一般に分子やその集合体といったものはハードウェアと考えられてきた。ところがナノスケールでは、自己集積の過程を例にとって考えると、ハードとソフトの区別があいまいになっていることが分かるだろう。とくにそのような発想に近いのが、「DNAコンピュータ」である。DNAコンピュータは塩基配列の中に特定の情報をプログラムして、そのDNA分子に自己処理をさせている。そして何種類か起こった処理のなかで、答えの候補となる反応物だけを取り出し、また再び同じような操作をして答えの候補を絞り込んでいく。そして最終的に残ったDNA分子には、私たちの欲しい答えが書かれているのだ。
このように分子に情報という概念をとり入れ、「分子プログラミング」をはじめて提唱したのは、おろらく超分子化学の生み親であるレーン(J.M.Lehn)だと言われている。レーンの著書「レーン 超分子化学(竹内敬人訳・化学同人)」のなかでは、さまざまな観点から、分子に情報という概念を取り込もうとしているのが伺える。
|
|
 |